
图解HTTP
图解HTTP
了解Web网络基础
**客户端:**通过发送请求获取服务器资源(例如:web浏览器)
web使用一种名为HTTP(HypterText Transfer Protocol,超文本传输协议)的协议作为规范,完成从客户端到服务器端等一系列运作流程。
网络基础TCP/IP
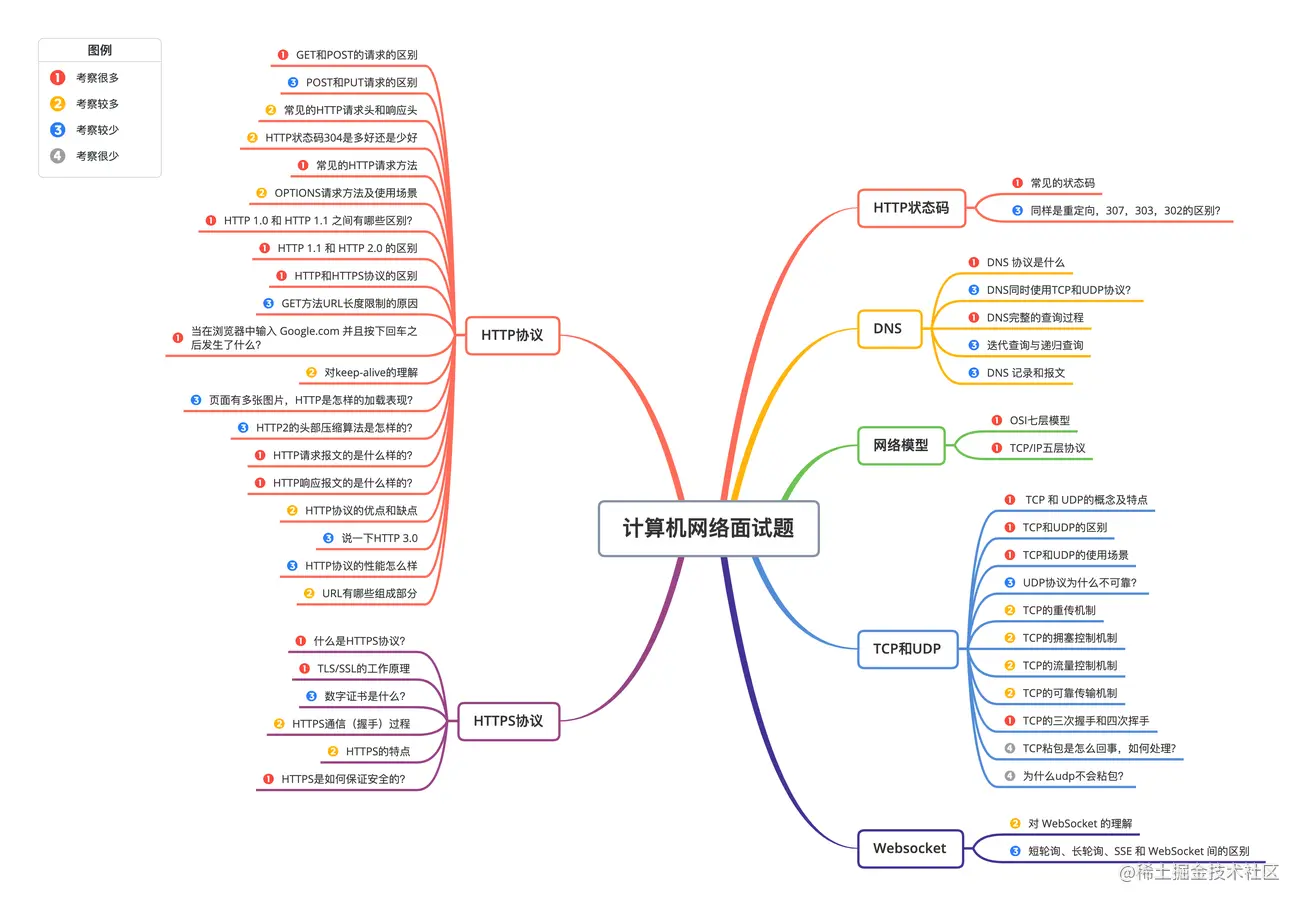
通常使用的网络(包括互联网)是在TCP/IP协议族的基础上运作的。而HTTP属于它内部的一个子集。
TCP/IP 协议族里重要的一点就是分层。TCP/IP 协议族按层次分别分为以下 4 层:应用层、传输层、网络层和数据链路层。
| 层次 | 作用 |
|---|---|
| 应用层 | 决定了向用户提供应用服务时通信的活动,如FTP文件传输协议)和DNS。 |
| 传输层 | 对上层应用层,提供处于网络连接中国的两台计算机之间的数据传输,如 TCP和UDP. |
| 网络层 | c处理在网络上流动的数据包,数据包是网络传输的最小数据单位,该层规定了通过怎样的路径到达对方计算机, |
| 链路层 | 用来处理连接网络的硬件部分。 |
TCP/IP 通信传输流
与 HTTP 关系密切的协议 : IP、TCP 和 DNS
IP(Internet Protocol)网际协议位于网络层
IP 协议的作用是把各种数据包传送给对方。而要保证确实传送到对方那里,则需要满足各类条件。其中两个重要的条件是 IP 地址(可变换)和 MAC 地址(是指网卡所属的固定地址)(Media Access Control Address)。
TCP三次握手
TCP 协议采用了三次握手 (three-way handshaking)策略。用 TCP 协议把数据包送出去后,TCP 不会对传送后的情况置之不理,它一定会向对方确认是否成功送达。握手过程中使用了 TCP 的标志(flag) —— SYN(synchronize) 和 ACK(acknowledgement)。

负责域名解析的 DNS 服务
DNS(Domain Name System)服务是和 HTTP 协议一样位于应用层的 协议。它提供域名到 IP 地址之间的解析服务。

总结:

URI 和 URL
URI:统一资源标识符(Uniform Resource Identifier)就是由某个协议方案表示的资源的定位标识符。协议方案是指访问资源所使用的协议类型名称。采用 HTTP 协议时,协议方案就是 http。
URL:统一资源定位符 用字符串标识某一互联网资源,而 URL表示资源的地点(互联网上所处的位置)。可见URL是 URI 的子集。

简单的 HTTP 协议
两种报文(一)
请求报文是由请求方法、请求URI、协议版本、可选的请求首部字段和内容实体构成的。

响应报文基本上由协议版本、状态码(表示请求成功或失败的数字代码)、用以解释状态码的原因短语、可选的响应首部字段以及实体主体构成。

HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个级别,协议对于发送过的请求或响应都不做持久化处理。为了实现期望的保持状态功能,于是引入了Cookie技术。有了Cookie再用HTTP协议通信,就可以管理状态了。可以理解成Cookie是为了解决保持状态功能的作用。
告知服务器意图的HTTP方法
HTTP/1.1中可使用的方法。
①GET:获取资源
GET方法用来请求访问已被URI识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回;如果是像CGI(Common Gateway Interface,通用网关接口)那样的程序,则返回经过执行后的输出结果。


②POST:传输实体主体
POST方法用来传输实体的主体。虽然用GET方法也可以传输实体的主体,但一般不用GET方法进行传输,而是用POST方法。虽说POST的功能与GET很相似,但POST的主要目的并不是获取响应的主体内容。

③PUT:传输文件
PUT方法用来传输文件。就像FTP协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求URI指定的位置。但是,鉴于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件,存在安全性问题,因此一般的Web网站不使用该方法。若配合Web应用程序的验证机制,或架构设计采用REST(Representational State Transfer,表征状态转移)标准的同类Web网站,就可能会开放使用PUT方法。

④HEAD:获得报文首部
HEAD方法和GET方法一样,只是不返回报文主体部分。用于确认URI的有效性及资源更新的日期时间等。

⑤DELETE:删除文件
DELETE方法用来删除文件,是与PUT相反的方法。DELETE方法按请求URI删除指定的资源。但是,HTTP/1.1的DELETE方法本身和PUT方法一样不带验证机制,所以一般的Web网站也不使用DELETE方法。当配合Web应用程序的验证机制,或遵守REST标准时还是有可能会开放使用的。

⑥OPTIONS:询问支持的方法
OPTIONS方法用来查询针对请求URI指定的资源支持的方法。

⑦TRACE:追踪路径
TRACE方法是让Web服务器端将之前的请求通信环回给客户端的方法。
发送请求时,在Max-Forwards首部字段中填入数值,每经过一个服务器端就将该数字减1,当数值刚好减到0时,就停止继续传输,最后接收到请求的服务器端则返回状态码200 OK的响应。客户端通过TRACE方法可以查询发送出去的请求是怎样被加工修改/篡改的。这是因为,请求想要连接到源目标服务器可能会通过代理中转,TRACE方法就是用来确认连接过程中发生的一系列操作。
但是,TRACE方法本来就不怎么常用,再加上它容易引发XST(Cross-SiteTracing,跨站追踪)攻击,通常就更不会用到了。


⑧CONNECT:要求用隧道协议连接代理
CONNECT方法要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL(Secure Sockets Layer,安全套接层)和TLS(TransportLayer Security,传输层安全)协议把通信内容加密后经网络隧道传输。


下表列出了HTTP/1.0和HTTP/1.1支持的方法。另外,方法名区分大小写,注意要用大写字母。LINK和UNLINK已被HTTP/1.1废弃,不再支持。

持久连接节省通信量
HTTP协议的初始版本中,每进行一次HTTP通信就要断开一次TCP连接。HTTP协议的初始版本中,每进行一次HTTP通信就要断开一次TCP连接。当浏览一个包含多张图片的HTML页面,每次的请求都会造成无谓的TCP连接建立和断开,增加通信量的开销。
为解决上述TCP连接的问题,HTTP/1.1和一部分的HTTP/1.0想出了持久连接(HTTP Persistent Connections,也称为HTTP keep-alive或HTTP connectionreuse)的方法。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持TCP连接状态。(持久连接旨在建立1次TCP连接后进行多次请求和响应的交互)
持久连接的好处在于减少了TCP连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。另外,减少开销的那部分时间,使HTTP请求和响应能够更早地结束,这样Web页面的显示速度也就相应提高了。
在HTTP/1.1中,所有的连接默认都是持久连接,但在HTTP/1.0内并未标准化。虽然有一部分服务器通过非标准的手段实现了持久连接,但服务器端不一定能够支持持久连接。毫无疑问,除了服务器端,客户端也需要支持持久连接。
管线化
管线化技术出现后,不用等待响应亦可直接发送下一个请求。这样就能够做到同时并行发送多个请求,而不需要一个接一个地等待响应了。
比如,当请求一个包含10张图片的HTML Web页面,与挨个连接相比,用持久连接可以让请求更快结束。而管线化技术则比持久连接还要快。请求数越多,时间差就越明显。
返回结果的HTTP状态码
状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。
状态码如200 OK,以3位数字和原因短语组成。数字中的第一位指定了响应类别,后两位无分类。响应类别有以下5种。

只要遵守状态码类别的定义,即使改变RFC2616中定义的状态码,或服务器端自行创建状态码都没问题。仅记录在RFC2616上的HTTP状态码就达40种,若再加上WebDAV(Web-basedDistributed Authoring and Versioning,基于万维网的分布式创作和版本控制)(RFC4918、5842)和附加HTTP状态码(RFC6585)等扩展,数量就达60余种。别看种类繁多,实际上经常使用的大概只有14种。接下来,我们就介绍一下这些具有代表性的14个状态码。
2XX成功
200 OK

表示从客户端发来的请求在服务器端被正常处理了。在响应报文内,随状态码一起返回的信息会因方法的不同而发生改变。比如,使用GET方法时,对应请求资源的实体会作为响应返回;而使用HEAD方法时,对应请求资源的实体主体不随报文首部作为响应返回(即在响应中只返回首部,不会返回实体的主体部分)。
204 No Content

该状态码代表服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分。另外,也不允许返回任何实体的主体。比如,当从浏览器发出请求处理后,返回204响应,那么浏览器显示的页面不发生更新。一般在只需要从客户端往服务器发送信息,而对客户端不需要发送新信息内容的情况下使用。
206 Partial Content
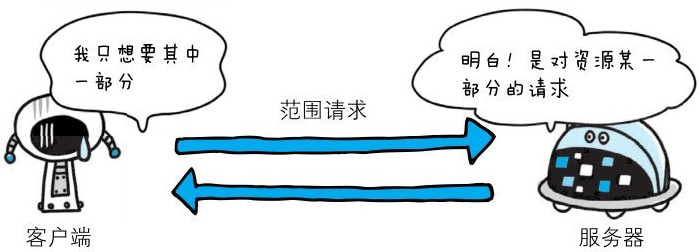
该状态码表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求。响应报文中包含由Content-Range指定范围的实体内容。
3XX重定向
3XX响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。
301 Moved Permanently
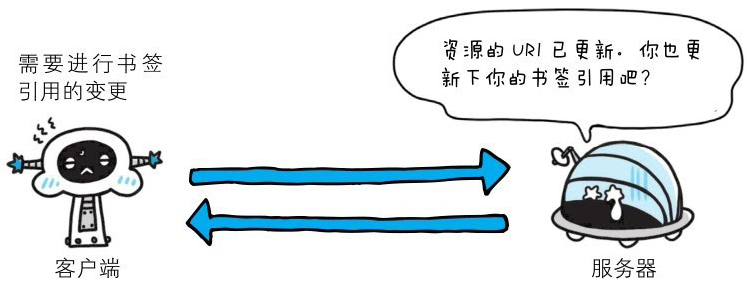
永久性重定向。该状态码表示请求的资源已被分配了新的URI,以后应使用资源现在所指的URI。也就是说,如果已经把资源对应的URI保存为书签了,这时应该按Location首部字段提示的URI重新保存。像下方给出的请求URI,当指定资源路径的最后忘记添加斜杠“/”,就会产生301状态码。(http://example.com/sample)
302 Found
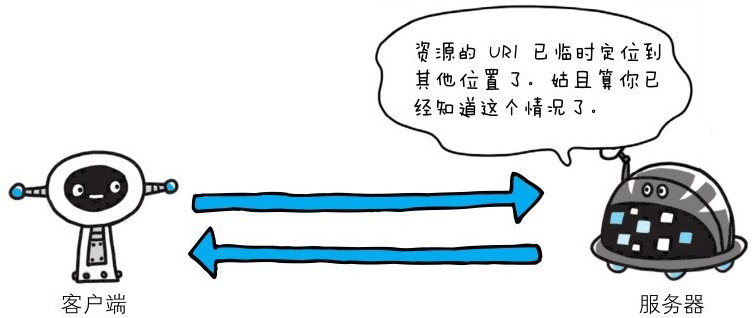
临时性重定向。该状态码表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问。和301 Moved Permanently状态码相似,但302状态码代表的资源不是被永久移动,只是临时性质的。换句话说,已移动的资源对应的URI将来还有可能发生改变。比如,用户把URI保存成书签,但不会像301状态码出现时那样去更新书签,而是仍旧保留返回302状态码的页面对应的URI。
303 See Other

该状态码表示由于请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源。303状态码和302 Found状态码有着相同的功能,但303状态码明确表示客户端应当采用GET方法获取资源,这点与302状态码有区别。
比如,当使用POST方法访问CGI程序,其执行后的处理结果是希望客户端能以GET方法重定向到另一个URI上去时,返回303状态码。虽然302 Found状态码也可以实现相同的功能,但这里使用303状态码是最理想的。
Tips: 当301、302、303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送。301、302标准是禁止将POST方法改变成GET方法的,但实际使用时大家都会这么做。
304 Not Modified
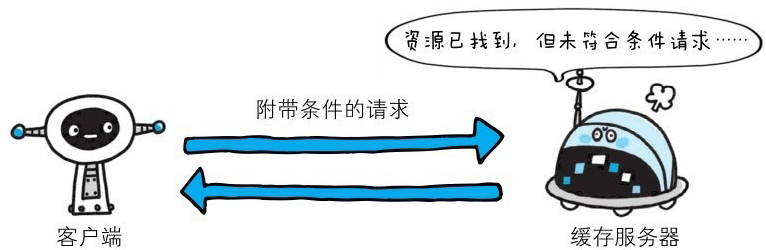
该状态码表示客户端发送附带条件的请求时,服务器端允许请求访问资源,但因发生请求未满足条件的情况后,直接返回304 Not Modified(服务器端资源未改变,可直接使用客户端未过期的缓存)。304状态码返回时,不包含任何响应的主体部分。304虽然被划分在3XX类别中,但是和重定向没有关系。
307 Temporary Redirect
临时重定向。该状态码与302 Found有着相同的含义。尽管302标准禁止POST变换成GET,但实际使用时大家并不遵守。
307会遵照浏览器标准,不会从POST变成GET。但是,对于处理响应时的行为,每种浏览器有可能出现不同的情况。
4XX客户端错误
4XX的响应结果表明客户端是发生错误的原因所在。
400 Bad Request
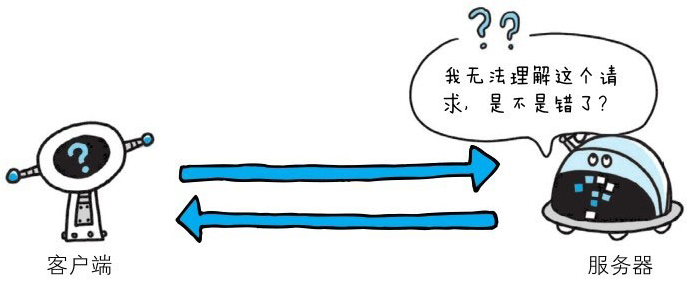
该状态码表示请求报文中存在语法错误。当错误发生时,需修改请求的内容后再次发送请求。另外,浏览器会像200 OK一样对待该状态码。
401 Unauthorized
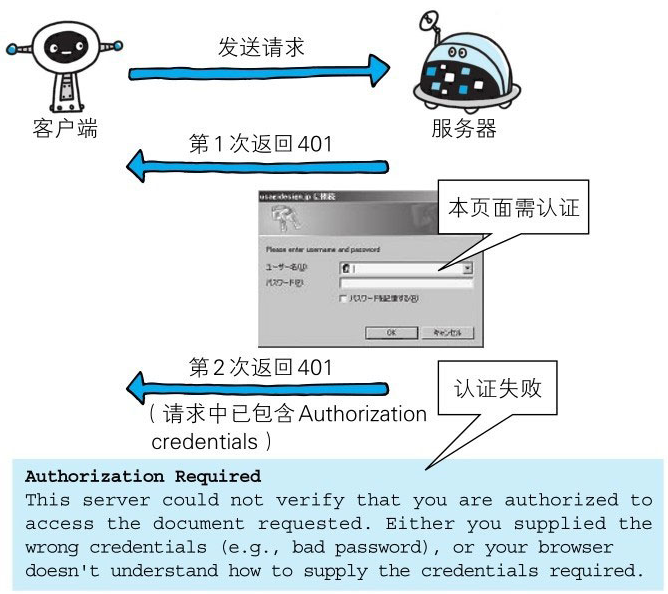
该状态码表示发送的请求需要有通过HTTP认证(BASIC认证、DIGEST认证)的认证信息。另外若之前已进行过1次请求,则表示用户认证失败。返回含有401的响应必须包含一个适用于被请求资源的WWW-Authenticate首部用以质询(challenge)用户信息。当浏览器初次接收到401响应,会弹出认证用的对话窗口。
403 Forbidden

该状态码表明对请求资源的访问被服务器拒绝了。服务器端没有必要给出拒绝的详细理由,但如果想作说明的话,可以在实体的主体部分对原因进行描述,这样就能让用户看到了。
未获得文件系统的访问授权,访问权限出现某些问题(从未授权的发送源IP地址试图访问)等列举的情况都可能是发生403的原因。
404 Not Found

该状态码表明服务器上无法找到请求的资源。除此之外,也可以在服务器端拒绝请求且不想说明理由时使用。
5XX服务器错误
5XX的响应结果表明服务器本身发生错误。
500 Internal Server Error

该状态码表明服务器端在执行请求时发生了错误。也有可能是Web应用存在的bug或某些临时的故障。
503 Service Unavailable
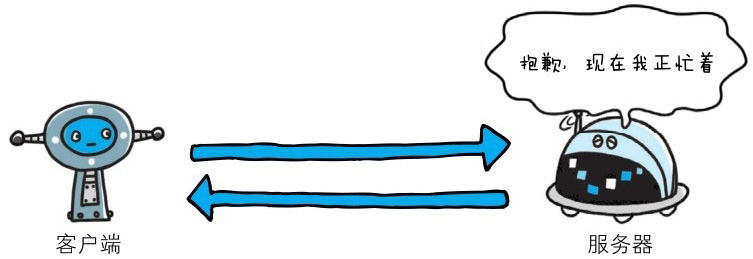
该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。如果事先得知解除以上状况需要的时间,最好写入Retry-After首部字段再返回给客户端。
状态码和状况的不一致:不少返回的状态码响应都是错误的,但是用户可能察觉不到这点。比如Web应用程序内部发生错误,状态码依然返回200 OK,这种情况也经常遇到。
两种报文(二)
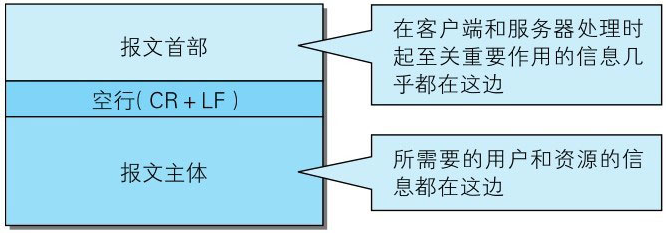
HTTP协议的请求和响应报文中必定包含HTTP首部。首部内容为客户端和服务器分别处理请求和响应提供所需要的信息。对于客户端用户来说,这些信息中的大部分内容都无须亲自查看。
HTTP请求报文:在请求中,HTTP报文由方法、URI、HTTP版本、HTTP首部字段等部分构成。

下面的示例是访问http://hackr.jp时,请求报文的首部信息。
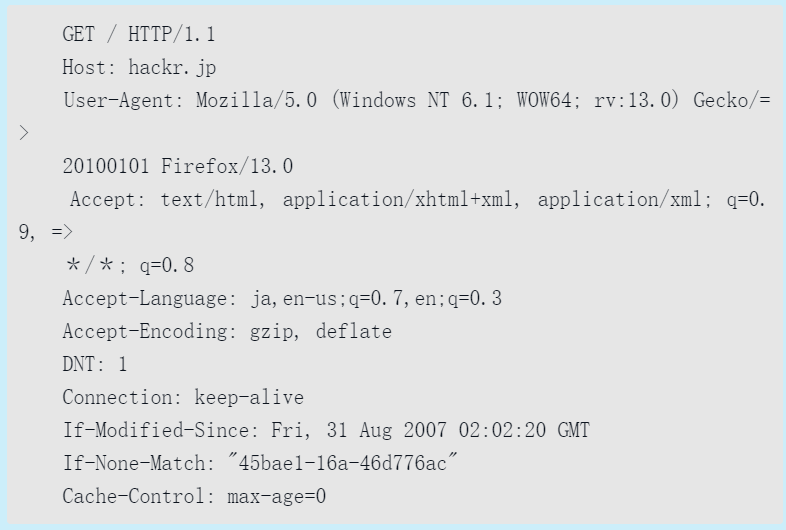
HTTP响应报文:在响应中,HTTP报文由HTTP版本、状态码(数字和原因短语)、HTTP首部字段3部分构成。

以下示例是之前请求访问http://hackr.jp/时,返回的响应报文的首部信息。
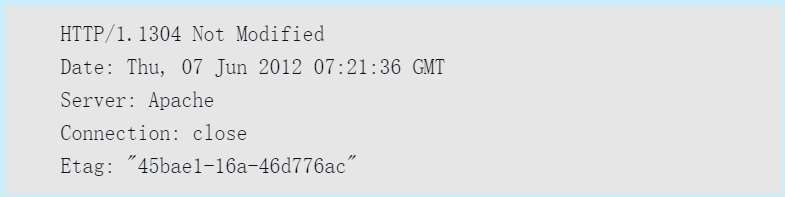
在报文众多的字段当中,HTTP首部字段包含的信息最为丰富。首部字段同时存在于请求和响应报文内,并涵盖HTTP报文相关的内容信息。因HTTP版本或扩展规范的变化,首部字段可支持的字段内容略有不同。本书主 要涉及HTTP/1.1及常用的首部字段。
为Cookie服务的首部字段
- Cookie的工作机制是用户识别及状态管理。Web网站为了管理用户的状态会通过Web浏览器,把一些数据临时写入用户的计算机内。接着当用户访问该Web网站时,可通过通信方式取回之前存放的Cookie。
- 调用Cookie时,由于可校验Cookie的有效期,以及发送方的域、路径、协议等信息,所以正规发布的Cookie内的数据不会因来自其他Web站点和攻击者的攻击而泄露。
为Cookie服务的首部字段

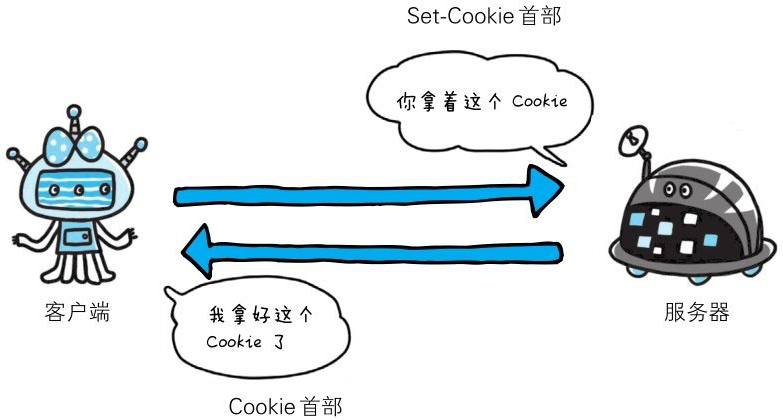
Set-Cookie中有一个httponly属性可以防止xss攻击。
HttpOnly属性:Cookie的HttpOnly属性是Cookie的扩展功能,它使JavaScript脚本无法获得Cookie。其主要目的为防止跨站脚本攻击(Cross-site scripting,XSS)对Cookie的信息窃取。无法在XSS中利用JavaScript劫持Cookie了
xss攻击
关于xss攻击的介绍可以看这篇博客——https://helloworldcoding.com/blog/article/6
确保Web安全的HTTPS
HTTP的缺点
到现在为止,我们已了解到HTTP具有相当优秀和方便的一面,然而HTTP并非只有好的一面,事物皆具两面性,它也是有不足之处的。HTTP主要有这些不足,例举如下。
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已遭篡改
这些问题不仅在HTTP上出现,其他未加密的协议中也会存在这类问题。除此之外,HTTP本身还有很多缺点。而且,还有像某些特定的Web服务器和特定的Web浏览器在实际应用中存在的不足(也可以说成是脆弱性或安全漏洞),另外,用Java和PHP等编程语言开发的Web应用也可能存在安全漏洞。
1.1 通信使用明文可能会被窃听
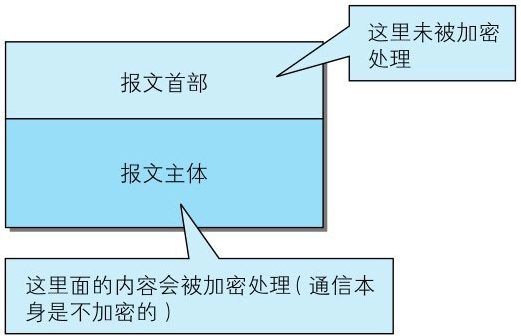
由于HTTP本身不具备加密的功能,所以也无法做到对通信整体(使用HTTP协议通信的请求和响应的内容)进行加密。即,HTTP报文使用明文(指未经过加密的报文)方式发送。
TCP/IP是可能被窃听的网络
如果要问为什么通信时不加密是一个缺点,这是因为,按TCP/IP协议族的工作机制,通信内容在所有的通信线路上都有可能遭到窥视。所谓互联网,是由能连通到全世界的网络组成的。无论世界哪个角落的服务器在和客户端通信时,在此通信线路上的某些网络设备、光缆、计算机等都不可能是个人的私有物,所以不排除某个环节中会遭到恶意窥视行为。即使已经过加密处理的通信,也会被窥视到通信内容,这点和未加密的通信是相同的。只是说如果通信经过加密,就有可能让人无法破解报文信息的含义,但加密处理后的报文信息本身还是会被看到的。
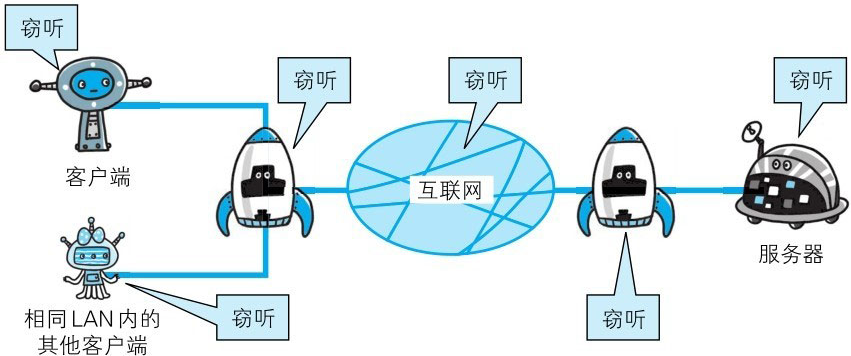
窃听相同段上的通信并非难事。只需要收集在互联网上流动的数据包(帧)就行了。对于收集来的数据包的解析工作,可交给那些抓包(PacketCapture)或嗅探器(Sniffer)工具。下面的图片示例就是被广泛使用的抓包工具Wireshark。它可以获取HTTP协议的请求和响应的内容,并对其进行解析。
像使用GET方法发送请求、响应返回了200 OK,查看HTTP响应报文的全部内容等一系列的事情都可以做到。

加密处理防止被窃听
在目前大家正在研究的如何防止窃听保护信息的几种对策中,最为普及的就是加密技术。加密的对象可以有这么几个。
- 通信的加密:一种方式就是将通信加密。HTTP协议中没有加密机制,但可以通过和SSL(Secure SocketLayer,安全套接层)或TLS(Transport LayerSecurity,安全传输层协议)的组合使用,加密HTTP的通信内容。用SSL建立安全通信线路之后,就可以在这条线路上进行HTTP通信了。==与SSL组合使用的HTTP被称为HTTPS(HTTP Secure,超文本传输安全协议)或HTTP over SSL。==

- 内容的加密:还有一种将参与通信的内容本身加密的方式。由于HTTP协议中没有加密机制,那么就对HTTP协议传输的内容本身加密。即把HTTP报文里所含的内容进行加密处理。在这种情况下,客户端需要对HTTP报文进行加密处理后再发送请求。诚然,为了做到有效的内容加密,前提是要求客户端和服务器同时具备加密和解密机制。主要应用在Web服务中。有一点必须引起注意,由于该方式不同于SSL或TLS将整个通信线路加密处理,所以内容仍有被篡改的风险。稍后我们会加以说明。
1.2 不验证通信方的身份就可能遭遇伪装
HTTP协议中的请求和响应不会对通信方进行确认。也就是说存在“服务器是否就是发送请求中URI真正指定的主机,返回的响应是否真的返回到实际提出请求的客户端”等类似问题。
任何人都可发起请求
在HTTP协议通信时,由于不存在确认通信方的处理步骤,任何人都可以发起请求。另外,服务器只要接收到请求,不管对方是谁都会返回一个响应(但也仅限于发送端的IP地址和端口号没有被Web服务器设定限制访问的前提下)。
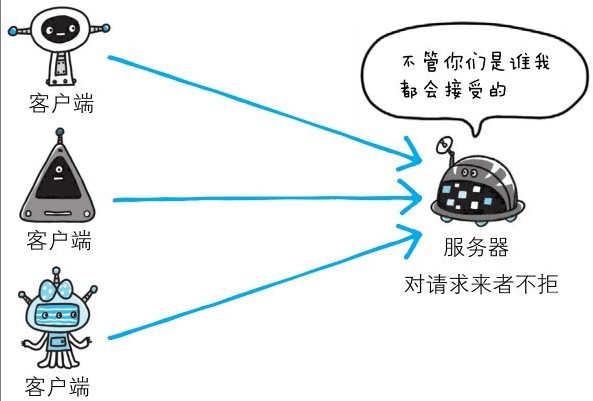
HTTP协议的实现本身非常简单,不论是谁发送过来的请求都会返回响应,因此不确认通信方,会存在以下各种隐患。
- 无法确定请求发送至目标的Web服务器是否是按真实意图返回响应的那台服务器。有可能是已伪装的Web服务器。
- 无法确定响应返回到的客户端是否是按真实意图接收响应的那个客户端。有可能是已伪装的客户端。
- 无法确定正在通信的对方是否具备访问权限。因为某些Web服务器上保存着重要的信息,只想发给特定用户通信的权限。
- 无法判定请求是来自何方、出自谁手。
- 即使是无意义的请求也会照单全收。无法阻止海量请求下的DoS攻击(Denial ofService,拒绝服务攻击)。
查明对手的证书
虽然使用HTTP协议无法确定通信方,但如果使用SSL则可以。SSL不仅提供加密处理,而且还使用了一种被称为证书的手段,可用于确定方。
证书由值得信任的第三方机构颁发,用以证明服务器和客户端是实际存在的。另外,伪造证书从技术角度来说是异常困难的一件事。所以只要能够确认通信方(服务器或客户端)持有的证书,即可判断通信方的真实意图。
通过使用证书,以证明通信方就是意料中的服务器。这对使用者个人来讲,也减少了个人信息泄露的危险性。另外,客户端持有证书即可完成个人身份的确认,也可用于对Web网站的认证环节。
1.3 无法证明报文完整性,可能已遭篡改
所谓完整性是指信息的准确度。若无法证明其完整性,通常也就意味着无法判断信息是否准确。
接收到的内容可能有误
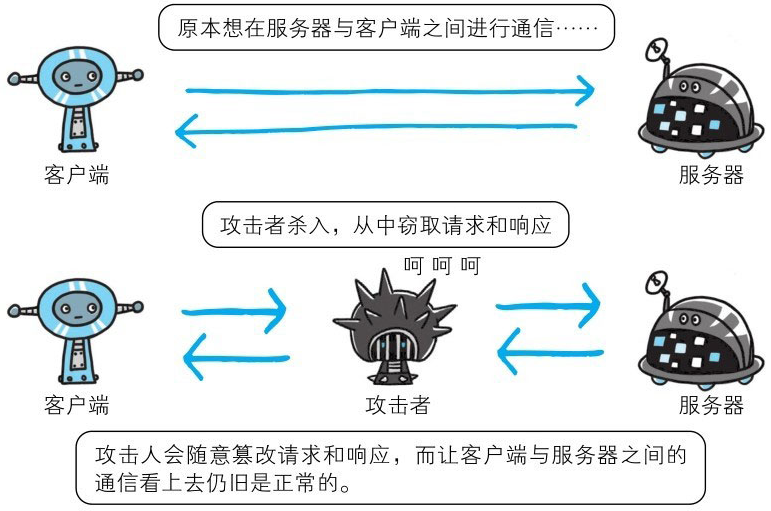
由于HTTP协议无法证明通信的报文完整性,因此,在请求或响应送出之后直到对方接收之前的这段时间内,即使请求或响应的内容遭到篡改,也没有办法获悉。
换句话说,没有任何办法确认,发出的请求/响应和接收到的请求/响应是前后相同的。

比如,从某个Web网站上下载内容,是无法确定客户端下载的文件和服务器上存放的文件是否前后一致的。文件内容在传输途中可能已经被篡改为其他的内容。即使内容真的已改变,作为接收方的客户端也是觉察不到的。
像这样,请求或响应在传输途中,遭攻击者拦截并篡改内容的攻击称为中间人攻击(Man-in-the-Middle attack,MITM)。
如何防止篡改
虽然有使用HTTP协议确定报文完整性的方法,但事实上并不便捷、可靠。其中常用的是MD5和SHA-1等散列值校验的方法,以及用来确认文件的数字签名方法。

提供文件下载服务的Web网站也会提供相应的以PGP(Pretty Good Privacy,完美隐私)创建的数字签名及MD5算法生成的散列值。PGP是用来证明创建文件的数字签名,MD5是由单向函数生成的散列值。不论使用哪一种方法,都需要操纵客户端的用户本人亲自检查验证下载的文件是否就是原来服务器上的文件。浏览器无法自动帮用户检查。
可惜的是,用这些方法也依然无法百分百保证确认结果正确。因为PGP和MD5本身被改写的话,用户是没有办法意识到的。
为了有效防止这些弊端,有必要使用HTTPS、SSL提供认证和加密处理及摘要功能。仅靠HTTP确保完整性是非常困难的,因此通过和其他协议组合使用来实现这个目标。
HTTP加上加密处理和认证以及完整性保护后即是HTTPS
如果在HTTP协议通信过程中使用未经加密的明文,比如在Web页面中输入信用卡号,如果这条通信线路遭到窃听,那么信用卡号就暴露了。另外,对于HTTP来说,服务器也好,客户端也好,都是没有办法确认通信方的。因为很有可能并不是和原本预想的通信方在实际通信。并且还需要考虑到接收到的报文在通信途中已经遭到篡改这一可能性。
为了统一解决上述这些问题,需要在HTTP上再加入加密处理和认证等机制。我们把添加了加密及认证机制的HTTP称为HTTPS(HTTP Secure)。
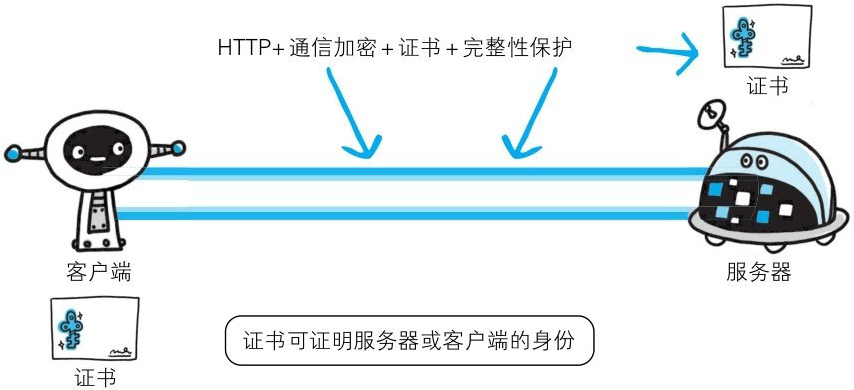
经常会在Web的登录页面和购物结算界面等使用HTTPS通信。使用HTTPS通信时,不再用http://,而是改用https://。另外,当浏览器访问HTTPS通信有效的Web网站时,浏览器的地址栏内会出现一个带锁的标记。对HTTPS的显示方式会因浏览器的不同而有所改变。

HTTPS是身披SSL外壳的HTTP
HTTPS并非是应用层的一种新协议。只是HTTP通信接口部分用SSL(Secure Socket Layer)和TLS(Transport Layer Security)协议代替而已。
通常,HTTP直接和TCP通信。当使用SSL时,则演变成先和SSL通信,再由SSL和TCP通信了。简言之,所谓HTTPS,其实就是身披SSL协议这层外壳的HTTP。
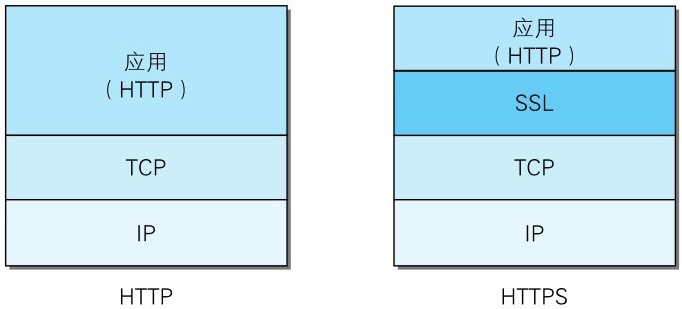
在采用SSL后,HTTP就拥有了HTTPS的加密、证书和完整性保护这些功能。SSL是独立于HTTP的协议,所以不光是HTTP协议,其他运行在应用层的SMTP和Telnet等协议均可配合SSL协议使用。可以说SSL是当今世界上应用最为广泛的网络安全技术。
相互交换密钥的公开密钥加密技术
在对SSL进行讲解之前,我们先来了解一下加密方法。SSL采用一种叫做公开密钥加密(Public-keycryptography)的加密处理方式。
近代的加密方法中加密算法是公开的,而密钥却是保密的。通过这种方式得以保持加密方法的安全性。加密和解密都会用到密钥。没有密钥就无法对密码解密,反过来说,任何人只要持有密钥就能解密了。如果密钥被攻击者获得,那加密也就失去了意义。
共享密钥加密的困境
加密和解密同用一个密钥的方式称为共享密钥加密(Common key crypto system),也被叫做对称密钥加密。
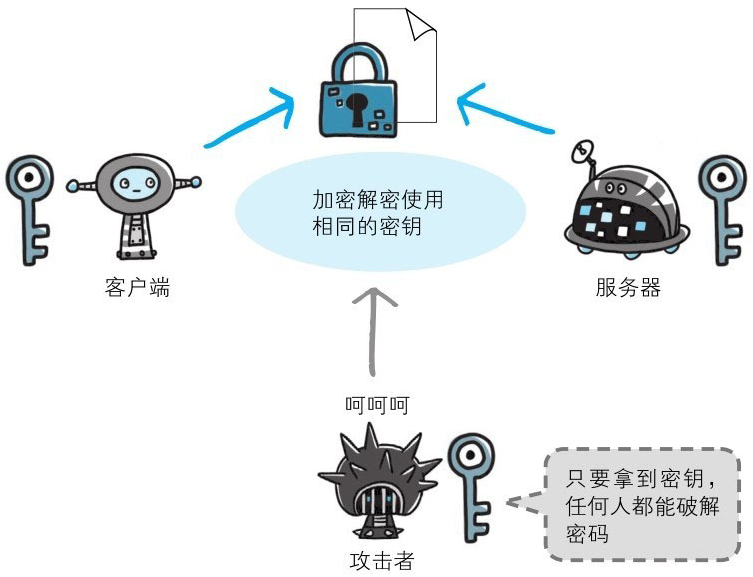
以共享密钥方式加密时必须将密钥也发给对方。可究竟怎样才能安全地转交?在互联网上转发密钥时,如果通信被监听那么密钥就可会落入攻击者之手,同时也就失去了加密的意义。另外还得设法安全地保管接收到的密钥。
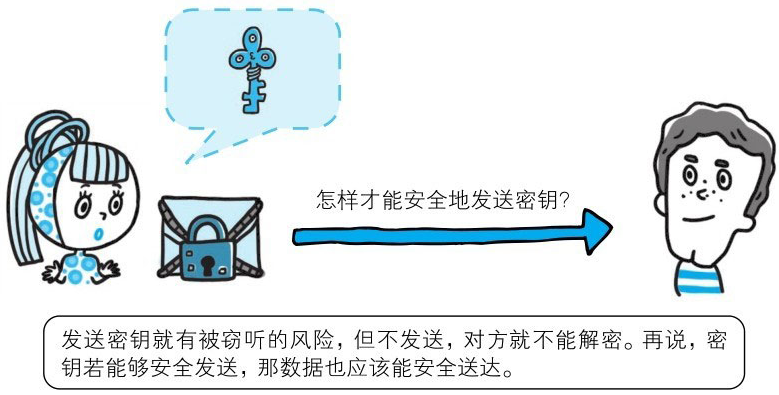
使用两把密钥的公开密钥加密
公开密钥加密方式很好地解决了共享密钥加密的困难。公开密钥加密使用一对非对称的密钥。一把叫做私有密钥(private key),另一把叫做公开密钥(public key)。顾名思义,私有密钥不能让其他任何人知道,而公开密钥则可以随意发布,任何人都可以获得。
使用公开密钥加密方式,发送密文的一方使用对方的公开密钥进行加密处理,对方收到被加密的信息后,再使用自己的私有密钥进行解密。利用这种方式,不需要发送用来解密的私有密钥,也不必担心密钥被攻击者窃听而盗走。
另外,要想根据密文和公开密钥,恢复到信息原文是异常困难的,因为解密过程就是在对离散对数进行求值,这并非轻而易举就能办到。退一步讲,如果能对一个非常大的整数做到快速地因式分解,那么密码破解还是存在希望的。但就目前的技术来看是不太现实的。
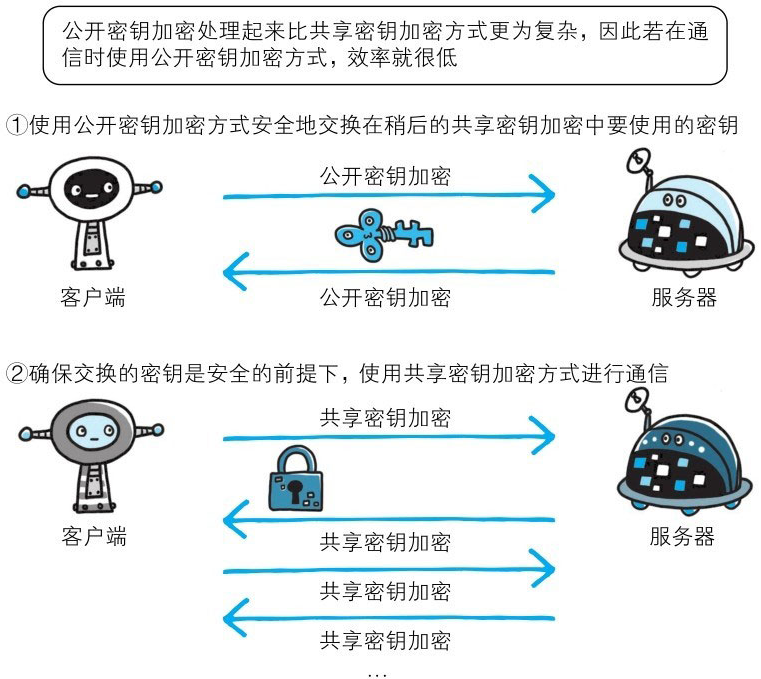
HTTPS采用混合加密机制
HTTPS采用共享密钥加密和公开密钥加密两者并用的混合加密机制。若密钥能够实现安全交换,那么有可能会考虑仅使用公开密钥加密来通信。但是公开密钥加密与共享密钥加密相比,其处理速度要慢。
所以应充分利用两者各自的优势,将多种方法组合起来用于通信。在交换密钥环节使用公开密钥加密方式,之后的建立通信交换报文阶段则使用共享密钥加密方式。
证明公开密钥正确性的证书
服务器会将由数字证书认证机构颁发的公钥证书发送给客户端,以进行公开密钥加密方式通信。公钥证书也可叫做数字证书或直接称为证书。
接到证书的客户端可使用数字证书认证机构的公开密钥,对那张证书上的数字签名进行验证,一旦验证通过,客户端便可明确两件事:一,认证服务器的公开密钥的是真实有效的数字证书认证机构。二,服务器的公开密钥是值得信赖的。
此处认证机关的公开密钥必须安全地转交给客户端。使用通信方式时,如何安全转交是一件很困难的事,因此,多数浏览器开发商发布版本时,会事先在内部植入常用认证机关的公开密钥。
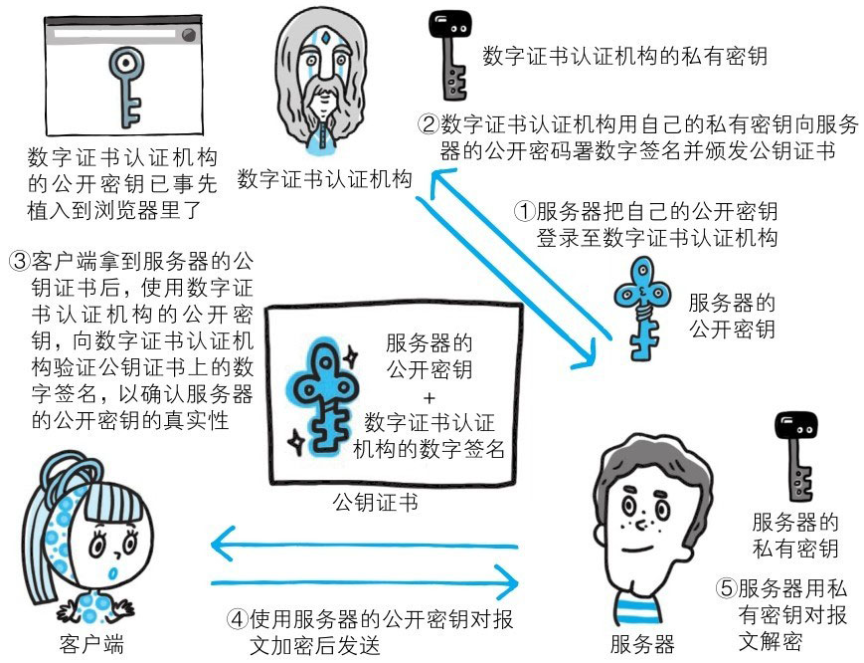
用以确认客户端的客户端证书
HTTPS中还可以使用客户端证书。以客户端证书进行客户端认证,证明服务器正在通信的对方始终是预料之内的客户端,其作用跟服务器证书如出一辙。
但客户端证书仍存在几处问题点。其中的一个问题点是证书的获取及发布。想获取证书时,用户得自行安装客户端证书。但由于客户端证书是要付费购买的,且每张证书对应到每位用户也就意味着需支付和用户数对等的费用。另外,要让知识层次不同的用户们自行安装证书,这件事本身也充满了各种挑战。
现状是,安全性极高的认证机构可颁发客户端证书但仅用于特殊用途的业务。比如那些可支撑客户端证书支出费用的业务。例如,银行的网上银行就采用了客户端证书。在登录网银时不仅要求用户确认输入ID和密码,还会要求用户的客户端证书,以确认用户是否从特定的终端访问网银。
客户端证书存在的另一个问题点是,客户端证书毕竟只能用来证明客户端实际存在,而不能用来证明用户本人的真实有效性。也就是说,只要获得了安装有客户端证书的计算机的使用权限,也就意味着同时拥有了客户端证书的使用权限。
HTTPS通信(握手)过程

使用浏览器进行全双工通信的WebSocket
利用Ajax和Comet技术进行通信可以提升Web的浏览速度。但问题在于通信若使用HTTP协议,就无法彻底解决瓶颈问题。WebSocket网络技术正是为解决这些问题而实现的一套新协议及API。
当时筹划将WebSocket作为HTML5标准的一部分,而现在它却逐渐变成了独立的协议标准。WebSocket通信协议在2011年12月11日,被RFC6455- The WebSocket Protocol定为标准。
WebSocket的设计与功能
WebSocket,即Web浏览器与Web服务器之间全双工通信标准。其中,WebSocket协议由IETF定为标准,WebSocket API由W3C定为标准。仍在开发中的WebSocket技术主要是为了解决Ajax和Comet里XMLHttpRequest附带的缺陷所引起的问题。
WebSocket协议
一旦Web服务器与客户端之间建立起WebSocket协议的通信连接,之后所有的通信都依靠这个专用协议进行。通信过程中可互相发送JSON、XML、HTML或图片等任意格式的数据。由于是建立在HTTP基础上的协议,因此连接的发起方仍是客户端,而一旦确立WebSocket通信连接,不论服务器还是客户端,任意一方都可直接向对方发送报文。下面我们列举一下WebSocket协议的主要特点。
- 推送功能:支持由服务器向客户端推送数据的推送功能。这样,服务器可直接发送数据,而不必等待客户端的请求。
- 减少通信量:只要建立起WebSocket连接,就希望一直保持连接状态。和HTTP相比,不但每次连接时的总开销减少,而且由于WebSocket的首部信息很小,通信量也相应减少了。
- 握手·请求:为了实现WebSocket通信,在HTTP连接建立之后,需要完成一次“握手”(Handshaking)的步骤。为了实现WebSocket通信,需要用到HTTP的Upgrade首部字段,告知服务器通信协议发生改变,以达到握手的目的。Sec-WebSocket-Key字段内记录着握手过程中必不可少的键值。Sec-WebSocket-Protocol字段内记录使用的子协议。子协议按WebSocket协议标准在连接分开使用时,定义那些连接的名称。
- 握手·响应:对于之前的请求,返回状态码101 SwitchingProtocols的响应。Sec-WebSocket-Accept的字段值是由握手请求中的Sec-WebSocket-Key的字段值生成的。成功握手确立WebSocket连接之后,通信时不再使用HTTP的数据帧,而采用WebSocket独立的数据帧。

- WebSocket API:JavaScript可调用“The WebSocket API”(http://www.w3.org/TR/websockets/,由W3C标准制定)内提供的WebSocket程序接口,以实现WebSocket协议下全双工通信。以下为调用WebSocket API,每50ms发送一次数据的实例。
期盼已久的HTTP/2.0
目前主流的HTTP/1.1标准,自1999年发布的RFC2616之后再未进行过改订。SPDY和WebSocket等技术纷纷出现,很难断言HTTP/1.1仍是适用于当下的Web的协议。
负责互联网技术标准的IETF(InternetEngineering Task Force,互联网工程任务组)创立httpbis(Hypertext Transfer ProtocolBis,http://datatracker.ietf.org/wg/httpbis/)工作组,其目标是推进下一代HTTP——HTTP/2.0在2014年11月实现标准化。
HTTP/2.0的特点
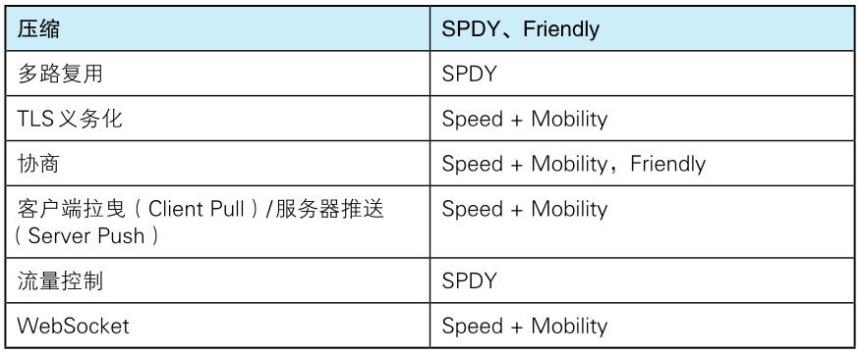
HTTP/2.0的目标是改善用户在使用Web时的速度体验。由于基本上都会先通过HTTP/1.1与TCP连接,现在我们以下面的这些协议为基础,探讨一下它们的实现方法。SPDY、HTTP Speed+Mobility、Network-Friendly HTTP Upgrade
HTTP Speed+Mobility由微软公司起草,是用于改善并提高移动端通信时的通信速度和性能的标准。它建立在Google公司提出的SPDY与WebSocket的基础之上。Network-Friendly HTTP Upgrade主要是在移动端通信时改善HTTP性能的标准。
HTTP/2.0的7项技术及讨论
HTTP/2.0围绕着主要的7项技术进行讨论,现阶段(2012年8月13日),大都倾向于采用以下协议的技术。但是,讨论仍在持续,所以不能排除会发生重大改变的可能性。
Web服务器管理文件的WebDAV
WebDAV(Web-based Distributed Authoringand Versioning,基于万维网的分布式创作和版本控制)是一个可对Web服务器上的内容直接进行文件复制、编辑等操作的分布式文件系统。它作为扩展HTTP/1.1的协议定义在RFC4918。
除了创建、删除文件等基本功能,它还具备文件创建者管理、文件编辑过程中禁止其他用户内容覆盖的加锁功能,以及对文件内容修改的版本控制功能。
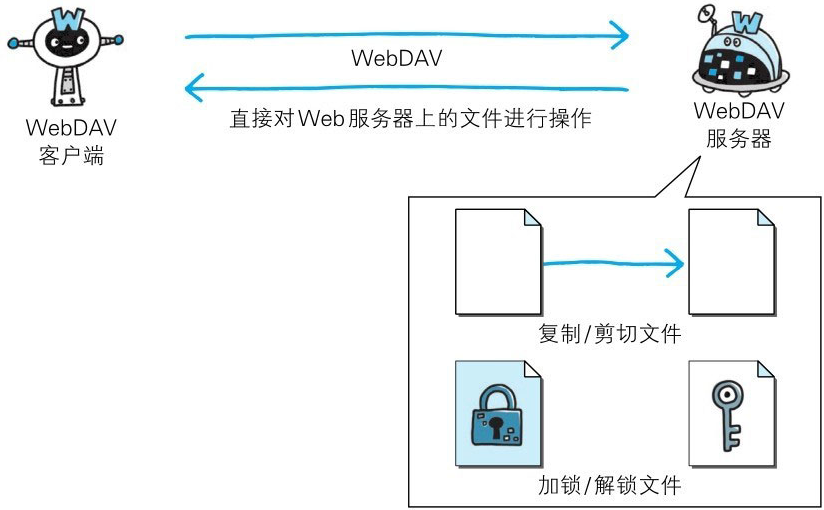
使用HTTP/1.1的PUT方法和DELETE方法,就可以对Web服务器上的文件进行创建和删除操作。可是出于安全性及便捷性等考虑,一般不使用。
 微信
微信 支付宝
支付宝