
数据库主键ID生成策略
数据库主键ID生成策略
前言
系统唯一ID是我们在设计一个系统的时候常常会遇见的问题。而生成数据库的ID有很多种方法,常见的有基于数据库的自增ID,Oracle 可以有sequence,MySQL可以使用auto_increment。在系统并发量不大的情况下,这些都是可行的办法。但是如果并发量比较大,数据库很快会成为整个系统的瓶颈。另外,有时候我们希望主键只是渐进递增,并不是逐个递增,比如订单表。因此这里就记录一下常见的数据库主键ID的生成策略。
常见的主键生成策略
数据库自增ID
基于数据库的自增ID完全可以实现主键ID的生成,例如在Mysql中建表时加上auto_increment。
优点:
- 实现简单,ID单调自增,数值类型查询速度快
缺点:
- DB单点存在宕机风险,无法扛住高并发场景
- 无法在写入数据之前获得数据的ID,必须要在提交数据库之后才会返回ID
- ID的产生依赖于数据库,会降低数据库性能
基于数据库集群模式
这个策略就是依据上个的方式进行优化,将其换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。但是这个需要对两个数据库进行设置防止生成重复的ID。
解决方案:分别设置起始值和自增步长

优点:
- 解决DB单点问题
缺点:
- 不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景。
使用集中的ID生成策略
也就是专门提供一个服务用于批量生成ID:例如利用redis的 incr命令实现ID的原子性自增。
但是用redis实现需要注意要考虑到redis持久化的问题,例:
RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
而且这种方式最大的缺陷是又引入一个外部系统,依赖外部系统又会带来新的不稳定性。
基于UUID
UUID大家都比较熟悉了,它有着全球唯一的特性,通过 MAC 地址、时间戳、命名空间、随机数、伪随机数来保证生成 ID 的唯一性。
优点:
- 生成足够简单,本地生成无网络消耗,具有唯一性
- 在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对
缺点:
- 无序的字符串,不具备趋势自增特性
- 没有具体的业务含义
- 长度过长16 字节128位,36位长度的字符串,存储以及查询对MySQL的性能消耗较大,MySQL官方明确建议主键要尽量越短越好,作为数据库主键
UUID的无序性会导致数据位置频繁变动,严重影响性能。 - 传输数据量大
基于雪花算法模式——推荐使用
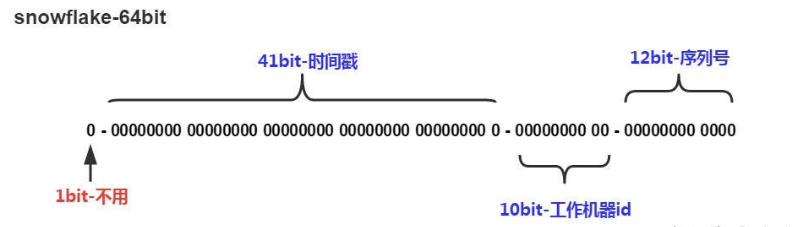
snowflake 是 Twitter 开源的分布式 ID 生成算法,结果是一个 long 型的 ID。其核心思想是时间戳+机器标识+自增序列的方式实现全局唯一ID:使用 41bit 作为毫秒数,10bit 作为机器的 ID(5 个 bit 是数据中心,5 个 bit 的机器 ID),12bit 作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是 0。snowflake 算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的 bit 数。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- ID 按照时间在单机上是递增的,渐进有序
- 没有引入外部服务,没有网络调用的开销,安全高效
缺点:
- 注意CPU时钟回拨的问题:在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
用go语言使用雪花算法实例:
1 | // 初始化 ID 生成器 |
其中还有其它基于Snowflake的衍生算法

结语
要根据业务的类型,确定适当的主键策略。在一些访问并发量和数据量并不是特别大的表上,使用数据库递增的策略也是可取的。甚至说没有必要使用Long作为主键的类型。而Snowflake算法的正确性是基于时间只能往前,不能后退的假设。这个假设在绝大多数时候都是成立的。
 微信
微信 支付宝
支付宝